
DeepJiandu数据集图像示例。
新甘肃客户端讯(新甘肃客户端记者 李萍)近日,西北师范大学联合甘肃简牍博物馆推出首个专门用于简牍字符检测与识别的大规模数据集——DeepJiandu数据集。
据了解,该数据集共包含7416张图像,标注了99852个字符,涵盖2242个类别,填补了简牍智能计算研究数据集的空白,标志着我国简牍智能计算研究取得重要进展,将为简牍文献的智能研究与保护提供坚实基础,有效推动数字人文领域的持续创新与发展。该工作由西北师范大学简牍研究院、甘肃省简牍智能计算与数字人文工程研究中心张强教授团队具体开展,上海中西书局、甘肃文化出版社提供相关数据资源,西南大学参与算法在数据集上的验证工作。
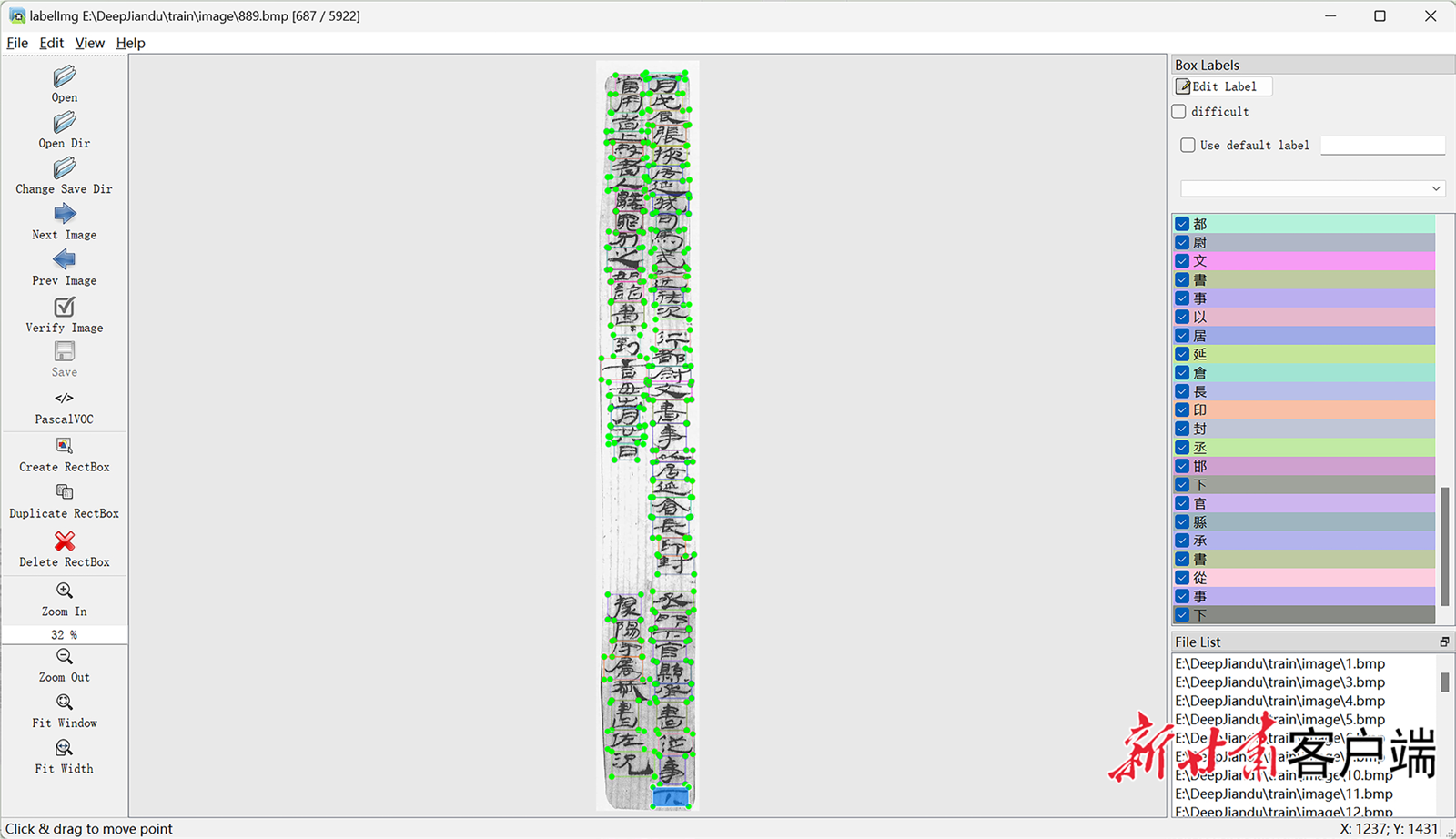
DeepJiandu数据集的字符标注示例,标注框标明了字符的位置和类别。
简牍是纸发明以前中国书籍的最主要形式,近年来,随着时光流转,这些珍贵的古籍文献面临着诸多挑战。特别是由于简牍材料的脆弱性以及长期埋藏环境,导致字符模糊、字迹缺损、布局复杂等问题,使得人工识别与整理极为困难。
DeepJiandu数据集的构建将有效解决这一问题。研究团队在前期简牍红外图像资料基础上,结合简牍学专家提供的释文信息,对图像进行了数字化加工处理和系统性字符标注。数据集涵盖2200余种字符类别,由简牍学专家与计算机专家合作标注,确保了数据专业性与准确性。同时,数据集设计考虑到简牍中字符的残损、异形字、多种布局等复杂场景,有效提升了模型对历史文献适应能力。
据介绍,研究团队基于超万件红外图像资料,最终筛选出7416张高质量红外图像。这些图像涵盖了不同的简牍材料、书写风格、字体特征,确保了数据的多样性。在数据预处理阶段,研究团队对图像进行了清理、噪声去除,并适当调整图像对比度,增强字符可辨识性。同时,所有标注工作由简牍学专家与计算机专家合作完成,保证了数据的学术价值与机器可读性。目前,该团队还在开展简牍图像融合、残断简缀合、简牍书写风格识别和简牍大模型等研究工作。
